

서 언
재료 및 방법
데이터셋 획득
데이터 분할, K-fold 교차 검증
데이터 증강, 하이퍼파라미터 최적화
딥러닝 모델 학습
모델 성능 평가
결과 및 고찰
덩굴모밀 잎의 생산량 예측 모델 구축 및 평가
덩굴모밀 줄기의 생산량 예측 모델 구축 및 평가
적 요
서 언
덩굴모밀(Persicaria chinensis)은 마디풀과(Polygonaceae)에 속하는 여러해살이풀로 동아시아, 인도, 북미지역에 분포하며, 우리나라에서는 제주도 남부 해안가에 제한적으로 자생하며, 산림청 지정 희귀식물로 세계자연보전연맹(IUCN)이 지정한 취약종(VU)이다(Korea National Arboretum, 2021). 또한 덩굴모밀은 항박테리아, 항균, 항염 활성을 가져 의약, 화장품, 건강기능식품 소재로 이용 가능성이 높으며(Hossen et al., 2015; Lai et al., 2012), 덩굴모밀 추출물의 면역과민 완화 효능과 관련된 특허 출원과 추출 조건에 따른 총 폴리페놀 함량 비교 연구가 수행되는 등 자원화가 진행되고 있다(Cho et al., 2024a; Choi et al., 2025; Luo et al., 2024).
인공지능(Artificial Intelligence, AI)은 인간의 학습과 추론 및 문제 해결 능력 등을 컴퓨터 시스템을 이용하여 구현하는 기술을 의미하며, 대규모 데이터로부터 패턴을 학습하고 이를 기반으로 예측과 의사결정을 수행할 수 있다(Collins et al., 2021). 최근 센서 기술과 데이터 수집 기술의 발달로 다양한 분야에서 대량의 데이터가 축적됨에 따라 복잡한 관계를 효과적으로 분석할 수 있는 인공지능 기술의 필요성이 증가하고 있다(Lăzăroiu et al., 2022). 특히 데이터 기반 학습을 통해 높은 예측 성능을 보이는 인공지능 기술이 최근 농업 및 자원식물 분야에서도 주목받고 있다(Chang and Park, 2023; Cho et al., 2024b; Park and Heo, 2022).
딥러닝(Deep Learning)은 인공지능의 하위 분야로 다층 신경망 구조를 이용하여 데이터의 고차원적 특징을 자동으로 학습하는 방법이다(Sarker, 2021). 딥러닝은 입력 데이터로부터 특징 추출과 예측의 동시 수행이 가능하여 사전에 정의된 특징을 이용해 학습하는 기계학습 방법에 비해 우수한 성능을 보인다(Razzaq and Shah, 2025). 특히 합성곱 신경망(Convolutional Neural Network, CNN)은 이미지 데이터의 공간적 구조를 효과적으로 학습할 수 있어 영상 인식, 객체 분류 및 회귀 문제에 널리 활용되고 있다(Ye et al., 2018). CNN 기반의 딥러닝 모델은 식물의 형태, 색상, 질감과 같은 시각적 정보를 정량화할 수 있어 식물 생육 및 생산량 예측에 적합하다(Pound et al., 2017).
식물의 생산량은 생육 환경와 생리적, 형태적 특성이 복합적으로 작용한 결과이며 요인 간의 관계가 복잡하다(Sadras and Richards, 2014). 기존의 생산량 예측 연구는 생육 지표나 환경 변수를 이용한 통계적 분석에 주로 의존해 예측에 한계가 있었다. 최근에는 식물 이미지를 활용한 딥러닝 기반의 예측 모델을 이용하여 비파괴적(Non-destructive) 방법으로 생산량을 예측하는 연구가 수행되고 있다(Lee et al., 2024). 따라서 본 연구에서는 희귀식물인 덩굴모밀의 자원화를 위한 초기 재배 단계부터 현장 적용할 수 있는 생장 모니터링 및 생산량 추정 모델을 구축하고자 하였다. 이에 생육 중인 덩굴모밀의 이미지를 이용하여 기능성 소재의 생산 평가에 직접적으로 이용되는 건중량을 부위별로 예측하기 위해 CNN 기본 모델과 CNN 기반의 전이학습 모델(VGG16, ResNet50, DenseNet121, MobileNetV2)을 적용하여 모델 간 예측 성능을 비교 분석하였다. 모델의 일반화 성능을 평가하기 위해 K-fold 교차검증과 독립적인 테스트 데이터셋을 사용하였으며, 이를 통해 희귀식물 덩굴모밀의 증식 및 보존과 재배 현장에서 적용 가능한 비파괴적인 딥러닝 기반의 생산량 예측 시스템 구축에 대한 정보를 제공하고자 하였다.
재료 및 방법
데이터셋 획득
본 연구에서 사용된 덩굴모밀은 국립세종수목원으로부터 식물체를 분양받았으며(관리번호 : SJNA2020-002103-001), 충북 옥천군 이원면 윤정리 산림바이오센터의 시험 온실에서 직경 30 ㎝ 화분에서 6월부터 10월까지 190개체를 재배하며, 높은 효율의 예측 모델 제작을 위해 식물체의 크기별로 균일하게 채취하였다. 채취한 덩굴모밀은 수세하여 이물질을 제거하고, 잎과 줄기로 나누어 40℃에서 48시간 동안 열풍 건조한 후 건중량을 측정하였다. 학습용 이미지는 삼성 갤럭시 S20+의 기본 카메라 어플리케이션을 통해 직접 촬영하여 개체당 1개의 단일이미지를 JPEG 형식의 이미지를 획득하였다(Table 1). 이후 학습용 이미지는 동일한 이미지를 이용하여 잎과 줄기의 생산량을 각각 예측하였으며, 원활한 학습을 위해 가로:세로의 비율이 1:1이 되도록 배경의 크기를 조절하였다(Fig. 1).
Table 1.
Distribution of leaf and stem dry weight data of P. chinensis used for deep learning model training.

데이터 분할, K-fold 교차 검증
모든 딥러닝 모델은 Python 3.9 환경에서 TensorFlow 및 Keras 라이브러리를 이용하여 구현하였다. 전체 데이터 중 10%를 무작위로 분할하여 예측 모델의 성능 평가를 위한 테스트 데이터셋으로 고정하였고, 테스트 데이터셋은 모델 학습 및 하이퍼파라미터 튜닝 과정에서 사용하지 않았다. 나머지 90%의 데이터는 모델 학습 및 검증에 사용하였다. 모델의 안정적인 성능 평가를 위해 학습 및 검증 데이터에 대해 K-fold 교차 검증(K = 5)을 수행하였으며, 검증 세트는 fold 간 상호 배타적으로 구성하였다. 데이터 수가 fold 수로 정확히 나누어떨어지지 않는 경우, fold 간 표본 수는 1개의 차이를 두고 균등하게 할당하였다. K-fold 교차 검증 과정에서 과적합을 방지하기 위해 early stopping 기법을 적용하였다. 검증 손실이 7 Epoch (patience = 7) 동안 개선되지 않을 경우 학습을 중단하고, 검증 손실이 최소일 때의 모델 가중치를 복원하였다.
데이터 증강, 하이퍼파라미터 최적화
모든 입력 이미지는 224 × 224 픽셀 크기로 조절한 후 픽셀 값을 0–1 범위로 정규화하였다. 모델의 과적합을 방지하고 제한된 데이터 수로도 학습 모델의 성능을 향상시키기 위해 학습 과정에서 실시간 데이터 증강(On-the-fly augmentation)을 적용하였다. 데이터 증강에는 회전, 좌우 이동, 상하 이동, 확대 및 축소, 좌우 반전과 밝기 변화가 포함되었으며, 검증과 테스트 데이터에는 데이터 증강을 적용하지 않았다.
각 모델의 성능을 최적화하기 위해 Keras Tuner를 이용하여 합성곱 필터 수, 학습에 사용되는 층의 범위(freeze layer), 완전결합층 노드 수, dropout 및 learning rate에 대한 하이퍼파라미터 탐색을 수행하였다(max trial = 20). 하이퍼파라미터 탐색은 K-fold 교차 검증을 기반으로 수행하였으며, 검증 손실이 최소가 되는 조합을 최적의 하이퍼파라미터로 선정하였다(Table 2).
Table 2.
Hyperparameter optimization results for CNN-based models used to predict leaf and stem yield of P. chinensis.
| Model | Filters | Frozen layersz | Dense units | Dropout | Learning rate |
| CNN | [16, 32] | - | 256 | 0.5 | 0.000779 |
| VGG16 | - | 9 | 128 | 0.5 | 0.000015 |
| ResNet50 | - | 130 | 256 | 0.1 | 0.000014 |
| DenseNet121 | - | 200 | 384 | 0.1 | 0.000295 |
| MobileNetV2 | - | 100 | 256 | 0.2 | 0.000182 |
딥러닝 모델 학습
덩굴모밀의 생산량 예측 모델 구축을 위해 이미지 학습에 적합한 CNN 기본 모델과 CNN 기반 전이학습 모델(VGG16, ResNet50, DenseNet121, MobileNetV2)을 사용하였다. CNN 기본 모델은 합성곱층, 최대 풀링층 및 완전결합층으로 구성하였으며, 합성곱층과 완전결합층에는 ReLU 활성화 함수를 적용하였다. 전이학습 모델의 경우 ImageNet 데이터셋으로 사전 학습된 가중치를 사용하였으며, 최상위 분류층을 제거한 후 회귀 문제에 적합하도록 완전결합층과 단일 출력층을 추가하였다. 완전결합층에는 ReLU 활성화 함수를 적용하였으며, 출력층에는 활성화 함수를 적용하지 않았다. 모든 모델은 Adam optimizer를 사용하여 학습하였으며, 손실 함수로 평균제곱오차(mean squared error, MSE)를 적용하였다. 추가적인 성능 지표로 평균절대오차(mean absolute error, MAE)를 함께 산출하였다. 모델 학습 시 Batch size는 8, Epoch는 50으로 설정하였다.
모델 성능 평가
덩굴모밀의 잎과 줄기 생산량 예측 모델을 구축한 후 각 모델 별로 전체 학습 데이터셋(90%)를 이용하여 재학습한 후(Epoch = 50), 초기에 분할한 테스트 데이터셋(10%)에 대해 성능 평가를 수행하였다. 평가 지표로는 결정계수(Coefficient of determination, R2), 평균절대오차(Mean absolute error, MAE), 평균제곱근오차(Root mean square error, RMSE)를 사용하였다.
결과 및 고찰
덩굴모밀 잎의 생산량 예측 모델 구축 및 평가
덩굴모밀 잎의 건중량 예측을 위해 CNN 기본 모델과 CNN 기반 전이학습 모델(VGG16, ResNet50, DenseNet121, MobileNetV2)을 적용하고, K-fold 교차 검증(K=5)을 통해 모델 성능을 평가하였다(Fig. 2). CNN 기본 모델은 R2가 0.36 ± 0.29로 가장 낮은 예측 성능을 보였으며, fold 간 변동성 또한 크게 나타났다. 이는 CNN의 처음부터 학습시키는 방식이 제한된 데이터 수를 이용하여 덩굴모밀 잎 생산량 예측에 충분한 일반화 성능을 확보하지 못했음을 의미한다. 반면, 전이학습 모델들은 모두 CNN 기본 모델에 비해 현저히 향상된 예측 성능을 보였다. VGG16 모델은 R2=0.74 ± 0.07을 기록하며 비교적 안정적인 성능을 나타냈고, ResNet50과 DenseNet121 모델은 각각 0.83 ± 0.08, 0.83 ± 0.06의 높은 결정계수를 보여 잎 건중량 예측에 가장 우수한 성능을 나타냈다. 특히 두 모델은 표준편차가 상대적으로 작아 교차 검증 과정에서도 안정적인 예측 성능을 유지하였다. MobileNetV2 모델은 R2=0.79 ± 0.07로 ResNet50과 DenseNet121보다는 다소 낮았으나 경량화된 구조임에도 불구하고 높은 예측 정확도를 보여 계산 효율성과 성능 간의 균형 측면에서 장점을 나타냈다(Table 3).
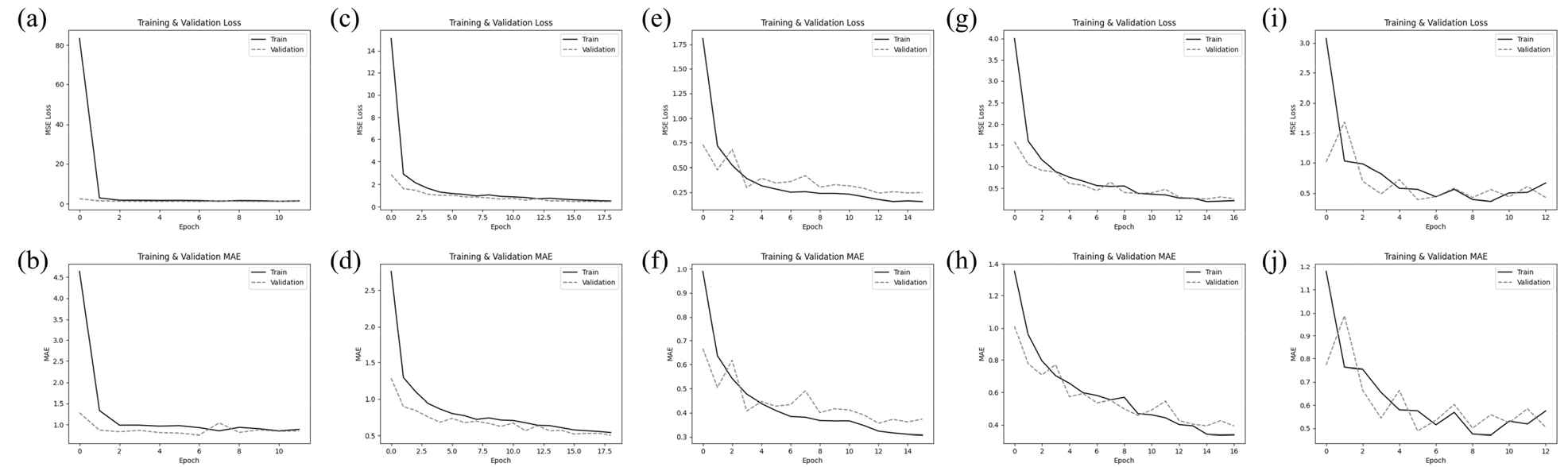
Table 3.
Performance of CNN-based models for predicting leaf yield of P. chinensis using K-fold cross-validation (K=5).
| Modelz | R2 | MAE | RMSE |
| CNN | 0.36±0.29 | 0.67±0.21 | 0.90±0.30 |
| VGG16 | 0.74±0.07 | 0.44±0.06 | 0.56±0.08 |
| ResNet50 | 0.83±0.08 | 0.33±0.03 | 0.45±0.04 |
| DenseNet121 | 0.83±0.06 | 0.33±0.03 | 0.44±0.04 |
| MobileNetV2 | 0.79±0.07 | 0.39±0.07 | 0.50±0.10 |
교차 검증 후 최적 하이퍼파라미터를 기반으로 전체 학습 데이터(90%)를 이용하여 모델을 재학습하고, 독립적인 테스트 데이터셋(10%)을 활용하여 최종 성능을 평가하였다(Table 4). 테스트 데이터셋 평가 결과에서도 교차 검증 결과와 유사한 경향이 나타났다. CNN 기본 모델은 R2=0.09로 매우 낮은 설명력을 보여 전이학습에 비해 예측 성능이 제한적임을 확인할 수 있었다(Gu and Lee, 2024). VGG16 모델은 R2=0.60으로 일정 수준의 예측력을 보였으나 고성능 모델 대비 성능 저하가 관찰되었다. ResNet50 모델은 R2=0.78을 기록하며 높은 예측 성능을 보였고, DenseNet121 모델은 R2=0.89로 모든 모델 중 가장 높은 성능을 나타냈다. 또한 DenseNet121은 MAE와 RMSE 값이 각각 0.22와 0.28으로 가장 낮아 예측 오차 측면에서도 가장 정확한 모델로 평가되었다. 이는 DenseNet 구조의 조밀한 연결(dense connectivity)이 특징 정보의 재사용을 통해여 비교적 적은 데이터 환경에서도 높은 일반화 성능을 확보하는 데 기여한 것으로 판단된다(Li et al., 2021). MobileNetV2 모델은 R2 =0.62로 중간 수준의 성능을 보였으며, 비교적 낮은 모델 복잡도를 고려할 때 실용적인 활용 가능성을 시사한다(Sandler et al., 2018).
Table 4.
Performance of CNN-based models for predicting leaf yield of P. chinensis evaluated on the independent test set.
| Modelz | R2 | MAE | RMSE |
| CNN | 0.09 | 0.72 | 0.82 |
| VGG16 | 0.60 | 0.38 | 0.55 |
| ResNet50 | 0.78 | 0.31 | 0.41 |
| DenseNet121 | 0.89 | 0.22 | 0.28 |
| MobileNetV2 | 0.62 | 0.39 | 0.53 |
덩굴모밀 줄기의 생산량 예측 모델 구축 및 평가
덩굴모밀 줄기의 건중량 예측을 위해 CNN 기본 모델과 CNN 기반 전이학습 모델(VGG16, ResNet50, DenseNet121, MobileNetV2)을 적용하고, K-fold 교차 검증(K=5)을 통해 모델 성능을 평가하였다(Fig. 3). CNN 기본 모델은 R2=0.49 ± 0.19로 비교적 낮은 예측 성능과 큰 표준편차를 보여 줄기 생산량 예측에서도 모델의 일반화 성능이 제한적임을 확인할 수 있었다. 전이학습 모델들은 모두 CNN 기본 모델 대비 우수한 성능을 보였다. VGG16 모델은 R2=0.83 ± 0.03으로 높은 예측력을 나타냈으며, ResNet50과 DenseNet121 모델은 각각 0.85 ± 0.04, 0.87 ± 0.03의 결정계수로 더욱 향상된 성능을 보였다. 특히 DenseNet121 모델은 MAE 0.73 ± 0.08, RMSE 1.01 ± 0.11으로 오차 측면에서도 우수한 결과를 나타냈다. MobileNetV2 모델은 R2=0.88 ± 0.02로 교차 검증 단계에서 가장 높은 결정계수를 보였으며, 표준편차 또한 매우 작아 fold 간 성능 변동성이 가장 낮았다(Table 5). 이는 경량화된 구조임에도 불구하고 줄기 생산량 예측에 필요한 주요 시각적 특징을 효과적으로 학습할 수 있음을 시사한다.
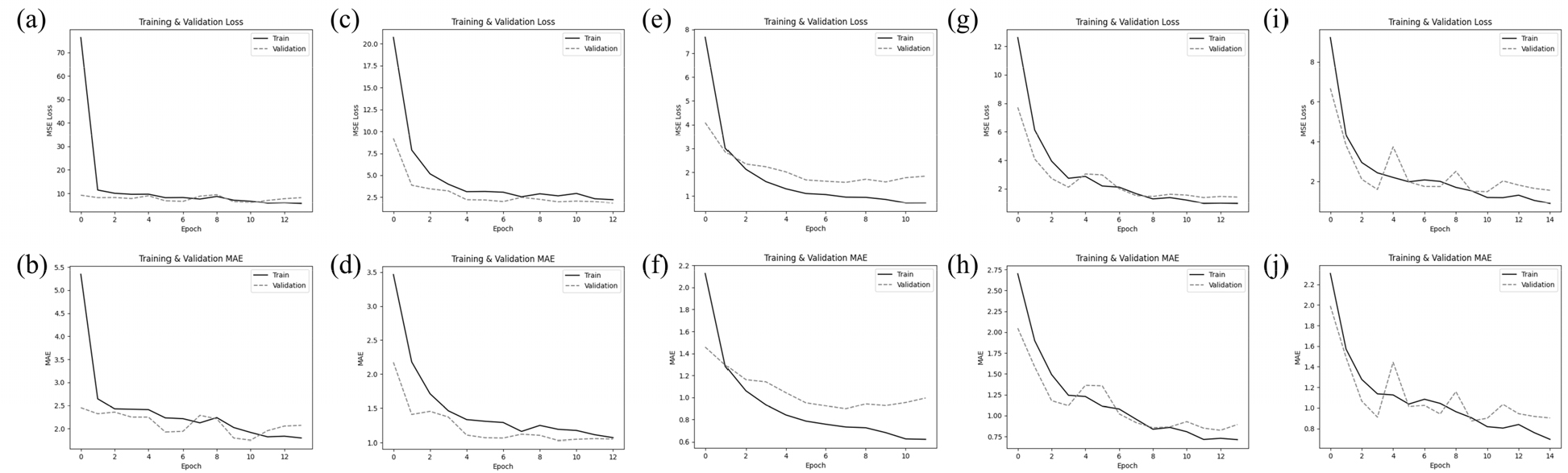
Table 5.
Performance of CNN-based models for predicting stem yield of P. chinensis using K-fold cross-validation (K=5).
| Modelz | R2 | MAE | RMSE |
| CNN | 0.49±0.19 | 1.47±0.25 | 1.99±0.42 |
| VGG16 | 0.83±0.03 | 0.88±0.09 | 1.17±0.07 |
| ResNet50 | 0.85±0.04 | 0.79±0.14 | 1.09±0.17 |
| DenseNet121 | 0.87±0.03 | 0.73±0.08 | 1.01±0.11 |
| MobileNetV2 | 0.88±0.02 | 0.74±0.04 | 1.00±0.04 |
교차 검증 후 최적 하이퍼파라미터를 적용하여 전체 학습 데이터(90%)로 모델을 재학습하고, 독립 테스트 데이터셋(10%)을 이용해 최종 성능을 평가하였다(Table 6). 테스트 데이터셋 평가 결과에서도 전이학습 모델들이 기본 CNN 모델보다 우수한 예측 성능을 보였다. CNN 기본 모델은 R2=0.56으로 다소 낮았으며, MAE와 RMSE 또한 가장 크게 나타났다. VGG16 모델은 R2=0.91로 테스트셋에서 가장 높은 결정계수를 기록하였으며, MAE=0.74 g, RMSE=1.06 g으로 전반적으로 안정적인 성능을 보였다. ResNet50과 DenseNet121 모델은 각각 R2=0.85, R2=0.84로 교차 검증 대비 다소 성능이 감소하였으나 여전히 높은 예측 정확도를 유지하였다. 반면, MobileNetV2 모델은 교차 검증에서는 가장 우수한 성능을 보였으나 테스트 데이터셋에서는 R2=0.79로 상대적으로 성능이 저하되는 것으로 나타났다. 이는 경량화 모델이 학습 데이터에는 적합하였으나 독립 데이터에 대해서는 일반화 성능이 다소 낮은 것으로 판단된다. 줄기는 길이와 직경의 변화가 건중량과 비교적 선형적인 관계를 가지며(Enquist et al., 1998), 줄기의 구조적 특성은 이미지상에서 안정적으로 관찰이 가능하다. 따라서 줄기 생산량 예측에서는 이미지 기반 딥러닝 모델이 시각적 정보를 더욱 효과적으로 활용할 수 있었던 것으로 판단된다. 또한 잎은 겹침, 중첩, 그림자 등에 의해 이미지상에서 일부 특징이 가려지는 경우가 많아 형태 정보의 손실이 발생했을 가능성도 있다. 이러한 결과는 이미지 기반 비파괴적 생산량 예측에서 예측 대상의 형태적인 안정성과 시각적인 명확성이 모델 성능에 중요한 영향을 미친다는 점을 보여준다(Zhang et al., 2020).
Table 6.
Performance of CNN-based models for predicting stem yield of P. chinensis evaluated on the independent test set.
| Modelz | R2 | MAE | RMSE |
| CNN | 0.56 | 1.69 | 2.37 |
| VGG16 | 0.91 | 0.74 | 1.06 |
| ResNet50 | 0.85 | 0.88 | 1.38 |
| DenseNet121 | 0.84 | 0.84 | 1.43 |
| MobileNetV2 | 0.79 | 1.15 | 1.66 |
본 연구에서는 제한된 데이터를 이용하여 구축한 생산 예측 모델의 상대적인 성능을 비교하여 희귀식물의 자원화 단계에서 반복적인 채취가 동반되는 방식의 샘플링을 대체해 생육 모니터링 및 초기 재배단계에서부터 딥러닝 기반의 생산량 예측 모델의 현장 적용이 가능함을 확인하였다. 향후 연구에서는 대량 재배 단계에서 다중 시점 이미지를 적용한 대규모의 데이터셋 확보와 예측값과 실측값에 대한 심층 분석을 통해 생산량 예측의 정확도를 향상시킬 수 있을 것으로 판단되며, 초분광카메라를 이용한 유용성분 함량 예측 연구도 가능할 것으로 기대된다.
적 요
본 연구는 희귀식물 덩굴모밀의 재배에 이미지 기반 딥러닝 모델의 성능을 비교하였으며, 이를 활용한 비파괴적 생산량 예측 기법 적용 가능성을 확인하였다. 잎의 생산량 예측에서 DenseNet121 모델은 교차 검증과 테스트 데이터셋 평가 모두에서 가장 우수한 성능을 나타내 데이터 확보가 제한적인 식물 자원 연구에서 효과적인 예측 모델로 활용될 수 있을 것으로 판단된다. 또한 줄기의 생산량 예측 결과, 전이학습 모델이 CNN 기본 모델보다 우수한 성능을 보여 잎의 경우와 유사한 양상을 보였다. 특히 교차 검증 단계에서는 MobileNetV2와 DenseNet121 모델이 높은 성능과 안정성을 보였으며, 테스트 데이터셋 평가에서는 VGG16 모델이 가장 높은 결정계수를 기록하였다. 이러한 결과는 향후 희귀식물인 덩굴모밀 재배의 자동화를 위한 생육 평가 및 생산량 예측 시스템 구축에 기초 자료로 활용될 수 있을 것이다.
