

서 언
재료 및 방법
식물재료 및 무기양분 측정
머신러닝 알고리즘(machine learning algorithms)
부트스트랩핑(bootstrapping) 및 데이터 분석
모델 성능평가
결과 및 고찰
모델의 파라미터 설정
부지화 잎의 무기양분과의 상관관계
질소결핍 여부를 판단하는 머신러닝 모델
적 요
서 언
질소는 과수작물의 생육에 가장 필수적인 다량원소로서 과수의 생산량을 결정짓는 중요한 요소이다. 질소는 식물체내 아미노산, 단백질, 여러 유기물 및 엽록체의 구성성분으로 사용되며(Tang et al., 2019), 광합성과 같은 대사과정에 중요한 역할을 담당하고 있다(Huang et al., 2021). 잎에 존재하는 질소의 75% 이상이 엽록체를 비롯한 광합성 기구에 존재하기 때문에 잎의 질소함량은 결국 식물체의 광합성 능력과 높은 상관관계를 갖는다(Field and Mooney, 1986; Tang et al., 2019). 따라서 질소결핍은 식물체의 광합성 능력을 저하시켜 잎, 줄기, 뿌리와 같은 기관의 생육을 저해하고 최종산물인 과일의 수확량을 감소시키게 된다. 생육기간동안 과수작물에 상당한 양의 질소질 비료를 공급하는데, 이는 영양생장뿐만 아니라 생식생장에도 충분한 질소를 공급하기 위함이다. 질소질 비료가 부족할 경우 낮은 생산량과 함께 소비자가 원하는 품질의 과일이 생산되지 않는다(Laacouri et al., 2018). 반면에 질소질 비료가 과다하게 되면 과일의 품질도 나빠지며(Park, 2003), 환경 및 수질오염을 야기하게 된다(Laacouri et al., 2018). 과일 비대기에는 과일의 질소요구도가 증가하여 잎이나 다른 기관의 질소가 이동하여 재배치되기도 한다(Rufat and DeJong, 2001). 따라서 고품질의 과일을 생산하기 위해서는 적절한 시기에 적당한 질소질 비료의 공급이 필요한데, 그러기 위해서는 반드시 식물체의 질소영양 상태를 정확하게 진단할 수 있어야 한다(Kim and Hong, 2007).
감귤(Citrus unshiu) 및 만감류(C. unshiu × C. sinensis)에서 질소가 결핍되면 나타나는 증상 중 가장 쉽게 판단할 수 있는 증상이 바로 잎의 황화 현상이다(Kang, 2006). 잎의 질소가 분해되어 다른 기관으로 이동하기 때문에 엽록체 함량이 줄어들어 잎이 노랗게 보이고 결국 노화되어 탈리가 일어나게 된다. 따라서 잎의 질소성분을 측정하는 것이 식물체내 질소부족을 판단할 수 있는 가장 빠른 방법이라 할 수 있다. 그러나 잎의 질소성분은 Kjeldahl법과 원소분석기를 이용하여 측정하는데 상당한 시간과 비용이 소요된다. 농촌진흥청을 비롯한 산하기관에서는 벼 잎의 질소성분을 분석하여 기준치보다 높을 경우 비료 시용을 허가하지 않는데, 이러한 엽분석은 오직 벼에만 국한되어 있다. 다른 작물은 엽분석을 통한 질소성분 조사가 어려워 시기 적절한 질소질 비료의 투입이 힘든 상황이다. 그에 비해 질소를 제외한 무기양분 조사는 유도결합 플라즈마 발광 분석법(Inductively Coupled Plasma Optical Emission Spectroscopy, ICP-OES)으로 조사가 가능하며(Eo et al., 2021; Lee et al., 2021), 여러 원소를 대상으로 상대적으로 쉽게 측정이 가능하다.
그래서 본 연구에서는 질소를 제외한 다른 무기양분 함량을 기반으로 하여 부지화(Shiranuhi) 잎의 질소성분의 결핍 여부를 구분할 수 있는 머신러닝 모델을 개발하고자 하였다. 이를 통해 질소함량을 직접적으로 분석할 수 없는 경우에 무기성분 함량에 기반하여 질소결핍 가능성 여부를 판단해 질소가 부족한 부지화 나무를 분별하고, 정확한 질소함량을 측정하게 유도하여 그에 기초한 적정 질소비료 시비를 가능케 하고자 하였다.
재료 및 방법
식물재료 및 무기양분 측정
제주대학교 포장 내 비닐하우스에 3년생 부지화를 수경재배 시스템에 재식한 후, 6개월 정도 부지화의 정상적인 생육을 유도한 후 시험재료로 활용하였다. 질소결핍구는 잎이 발생한 지 20일이 지난 후부터 질소만 제외한 양액을 공급하였고, 대조구는 측정을 시작한 20일부터 120일까지 계속 정상 양액을 공급하였다. 부지화 잎의 질소 및 무기원소 분석을 위해 채취한 잎을 증류수로 세척하고 70℃에서 24시간 건조시킨 후 분쇄하였다. 전 질소 함량은 건조된 시료 0.5 g을 켈달플라스크에 정확히 취하고 H2SO4-H2O2법으로 습식분해하여 Kjeldahl법으로 정량하였다. 무기성분은 건조된 시료 0.5 g을 분해플라스크에 넣고 왕수(염산 3 mL: 질산 1 mL) 분해법으로 분해시킨 후 인(P), 칼륨(K), 칼슘(Ca), 마그네슘(Mg), 붕소(B), 아연(Zn), 망간(Mn), 철(Fe), 구리(Cu) 함량은 ICP-OES (JY 138 Ultrace, Jobin Yvon, France)로 측정하였다(NIAST, 2000). 각 처리구마다 18반복을 수행하였다.
머신러닝 알고리즘(machine learning algorithms)
7종의 머신러닝 알고리즘을 이용하여 부지화 잎의 질소결핍 여부를 구분하는 모델을 구현하고 그 성능을 평가하였다: Stochastic Gradient Descent (SGD), Support Vector Machine (SVM), Adaptive Boosting (AdaBoost), k-Nearest Neighbors (kNN), Random Forest (RF), Naïve Bayes (NB), Gradient Boosting (GB). SGD는 경사하강법에서 배치 크기를 1로 설정하고 데이터를 무작위로 선택하여 적은 데이터로도 평균값을 추정할 수 있는 장점을 가지고 있다(Sun et al., 2021). 그러나 무작위 선택으로 인해 노이즈가 심한 단점이 있으며, 이로 인해 최저점을 찾지 못할 수도 있다. SVM은 데이터를 벡터 공간으로 맵핑하는 함수(kernel)를 이용해 각 클래스간의 거리를 최대화하는 결정경계를 찾는다(Hwangbo and Jeong, 2021). AdaBoost는 복수 개의 분류기를 결합하여 분석하는 앙상블 기법 중 하나로, 앞선 모형이 제대로 분류하지 못한 패턴을 더 집중적으로 학습하여 분류한다(Hwangbo and Jeong, 2021). kNN은 k개 이웃의 인접 관측치의 각 클래스별 비율을 이용하여 가장 비중이 높은 집단으로 결정하는 방법이다(Hwangbo and Jeong, 2021). 그러나 데이터셋이 클 경우, 근접 이웃을 찾는데 많은 시간이 소요되고 대표성이 떨어지는 관측치가 혼재되어 있을 경우 이를 제거해야 좋은 성능이 보장된다(Hwangbo and Jeong, 2021). RF는 데이터와 설명변수 모두에 임의성(randomness)을 반영해 모형의 정도를 높이는 알고리즘으로 분류 및 회귀 문제 모두 사용 가능한 방법이다(Kim et al., 2021). RF는 결정트리의 과적합을 피할 수 있는 장점이 있지만, 결정트리가 많으면 시간 소요가 큰 단점을 가지고 있다. NB모델은 데이터가 각 클래스에 속할 특징 확률을 계산하는 조건부 확률 기반의 분류방법이다(Shin, 2019). 간단하고 효율적이지만, 모든 특징들이 동등하며 독립적이라는 가정이 현실과는 잘 맞지 않을 수도 있다. GB는 AdaBoost와 마찬가지로 부스팅 알고리즘의 하나로, 약한 분류기를 결합하여 성능이 높아진 분류기를 만드는 알고리즘이다(Hwangbo and Jeong, 2021). RF를 비롯한 여타 머신러닝 모델 중 성능이 좋은 편에 속하지만, 수행시간이 오래 걸리고 하이퍼 파라미터 설정에 많은 노력이 필요한 단점이 있다(Kwon, 2020).
부트스트랩핑(bootstrapping) 및 데이터 분석
본 실험에 사용된 질소성분 및 기타 무기양분 측정 데이터는 36개로, 모델의 학습에 사용하기에는 충분하지 않았다. 그래서 부트스트랩핑(bootstrapping) 방법을 이용해 데이터를 증폭한 후 회귀분석 및 머신러닝 모델의 학습에 사용하였다. 부트스트랩핑은 기존 데이터에서 N개의 데이터를 복원추출(random sampling)한 후 평균한 값을 새로운 데이터로 사용하고, 이러한 과정을 여러 번 반복하여 기존의 데이터를 증폭시키는 방법이다(Kim et al., 2021). 부트스트랩핑은 독립변수와 종속변수가 선형관계에 있을 때 회귀분석에서 가장 유의미한 결과를 도출할 수 있다고 알려져 있다(Kim et al., 2021). 1,000여 개로 증가된 데이터는 학습(training)에만 사용하였고, 테스트(test)에는 본래 데이터만으로 시험하였다.
데이터 분석은 R 프로그램(ver. 4.1.2, R foundation for statistical computing, Vienna, Austria)에 다양한 패키지를 설치하여 분석하였다: “sgd” for SGD; “e1071” for SVM and NB; “caret” for kNN; “randomForest” for RF; “adabag” for AdaBoost; “gbm” for GB. 로지스틱 회귀분석(logistic regression, LR)은 다른 패키지 설치없이 R 프로그램만으로 분석하여 머신러닝 모델과 비교하였다. 또한, 본 논문의 모든 그래프는 R을 이용하여 작성하였다.
모델 성능평가
모델의 분류결과에 대한 평가척도는 여러 가지가 있는데 모두 혼동행렬(confusion matrix)에 기반하고 있다(Jang and Lee, 2021). 혼동행렬은 모델의 실제 클래스와 예측 클래스 간의 오류값을 보여주는데, True Positive (TP)는 실제값이 맞는 것을 올바르게 예측한 것이며, True Negative (TN)는 틀린 것을 올바르게 틀렸다고 예측한 것이다. False Positive (FP)는 틀린 것을 맞다고 잘못 예측한 것이며, False Negative (FN)는 맞는 것을 틀렸다고 잘못 예측한 것이다. 위 값들을 조합해 분류기(classifier)의 성능을 측정하는 지표인 정확도(accuracy) [1], 정밀도(precision) [2], 재현율 또는 민감도(recall or sensitivity) [3], F1 score(정밀도와 재현율의 조화평균) [4]를 계산할 수 있다. ROC (receiver operation characteristic curve) 곡선은 민감도(sensitivity)와 특이도(specificity) [5]를 이용해 작성한 그래프로 false positive rate이 변할 때 true positive rate (재현율)이 어떻게 변하는지를 나타내는 곡선이다. AUC (area under curve)는 ROC 곡선 밑의 면적을 구한 값으로 1에 가까울수록 모델의 성능이 우수한 것으로 판단한다.
결과 및 고찰
모델의 파라미터 설정
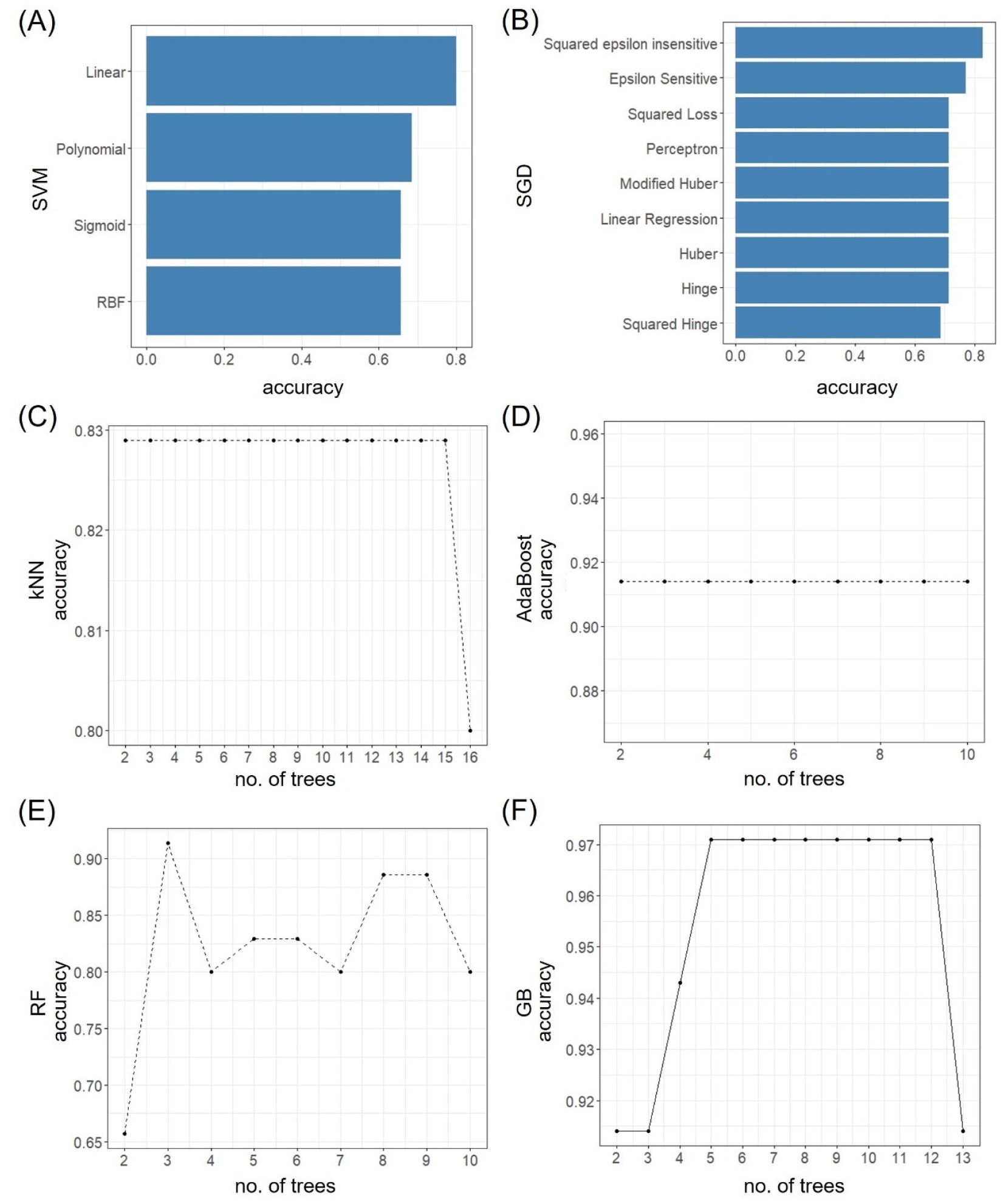
각 분류기의 분류성능을 높이기 위해서 정확도가 가장 높은 값일 때의 파라미터를 조사하였다(Fig. 1). SVM은 예측값을 근사하는 추정함수(kernel)로 linear, polynomial, sigmoid, rbf 네 가지가 있는데, Fig. 1A에서 보듯이 선형분류의 경우 정확도가 0.800으로 가장 높아 본 연구에서는 linear를 사용하였다. SGD의 경우, 다양한 손실함수를 설정할 수 있는데(Fig. 1B), squared ε insensitive로 설정하면 가장 높은 0.829의 정확도를 얻을 수 있었다. kNN 모델에서는 neighbors의 개수인 k를 2에서 16까지 조절한 결과, 15까지 0.829의 정확도를 보여주어 최소값인 2로 설정하여 분석하였다(Fig. 1C). AdaBoost는 tree의 수를 2에서 100까지 조절하였으나, 정확도 0.914에 차이가 생기지 않아 최소값인 2로 설정하였다(Fig. 1D). RF모델은 의사결정 tree의 수에 따라 정확도의 차이가 크게 발생하였으나, 3으로 설정하였을 때 가장 높은 0.914를 보였다(Fig. 1E). GB모델은 tree의 수에 따라 정확도의 수치에 큰 차이가 나지 않았으나 4에서 12까지 가장 높은 0.971의 정확도를 보여 최소값인 5로 설정하였다(Fig. 1F). GB모델의 학습률은 0.01부터 0.10까지 변경해 보았으나 모두 동일한 정확도를 보여 0.01로 설정하여 활용하였다.
부지화 잎의 무기양분과의 상관관계
부지화 질소결핍구와 대조구를 대상으로 잎의 질소 및 기타 무기양분을 측정하고 그 상관관계를 분석하였다(Fig. 2). 잎의 질소성분은 칼슘(r = 0.63), 망간(r = 0.55), 칼륨(r = 0.51)과 높은 정의 상관을 이루었다. 그 외의 다른 화학성분과는 낮은 상관을 보였지만(N-B: 0.10; N-Zn: 0.15; N-Cu: 0.12), 질소와 인, 마그네슘은 부의 상관을 이루는 것을 알 수 있었으며(r = -0.29, -0.05), 질소와 철도 약한 상관관계가 있었다(r = 0.29). 옥수수 종자에서는 질소 수준이 높아지면, 구리, 철, 마그네슘 및 망간의 농도는 증가하고 칼륨, 인 및 아연 함량은 낮아진다고 보고되었다(Guo et al., 2020). 벼에서는 질소처리에 의해 벼 식물체 내 칼슘 함량은 감소하고, 마그네슘 함량은 증가하며 인, 칼륨 흡수에는 영향을 미치지 않는다고 하였다(Jang et al., 2017). 이렇듯 질소농도 증가에 따른 무기성분의 함량 변화는 작물에 따라 각각 다른 양상을 보이는 것으로 생각된다.
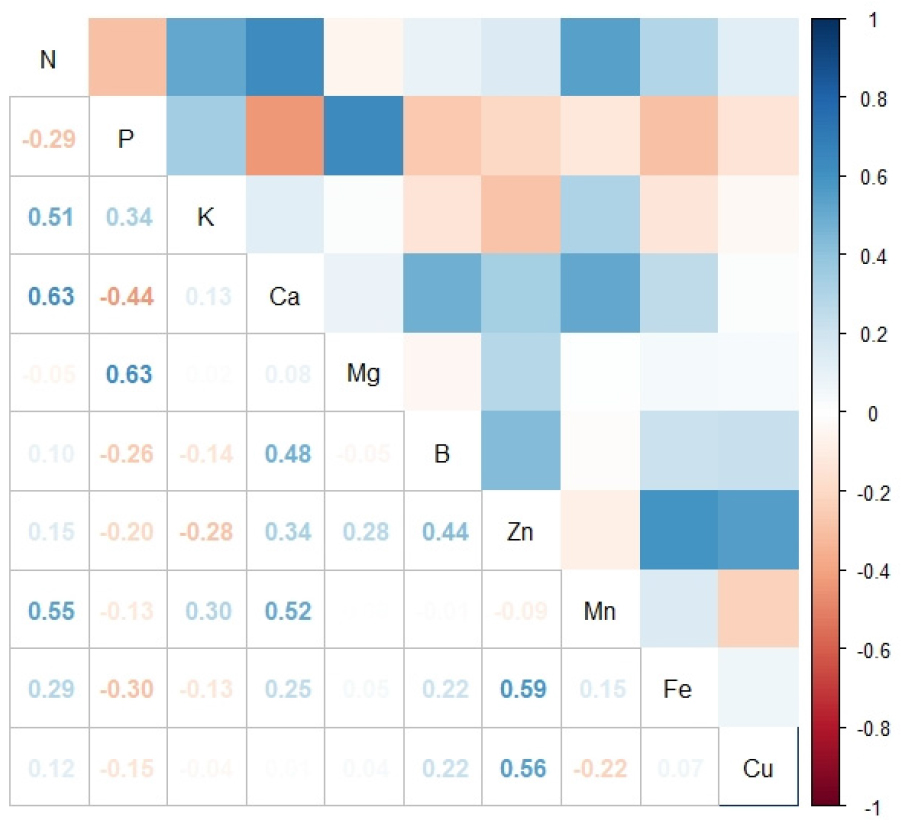
질소 외에 다른 화학성분들간의 상관관계를 보면, 칼슘과 붕소(r = 0.48)는 약한 상관관계가 있어 질소와 칼슘의 높은 상관관계로 인해 붕소는 질소의 결핍 여부를 구분하는데 약한 기여를 할 것으로 판단된다. 인은 마그네슘과 상관계수 0.63의 높은 상관을 보여주었고, 그 다음으로는 아연과 철(r = 0.59), 아연과 구리(r = 0.56), 칼슘과 망간(r = 0.52)순으로 높은 정의 상관을 보였다.
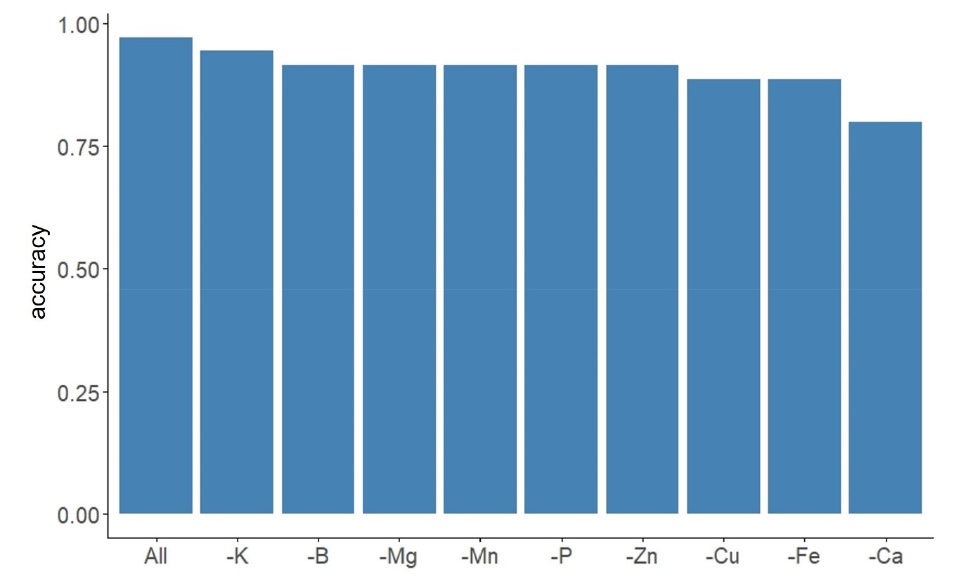
Fig. 3을 보면, 모든 무기성분을 포함하여 질소결핍 여부를 분별한 GB모델의 정확도와 무기성분 중 각 하나씩 제거한 모델들의 정확도를 비교하였다. 그 결과 질소함량과 상관관계가 가장 높은 칼슘이 제거되어 분석된 모델이 가장 낮은 정확도(0.800)를 보였다. 그 다음으로 철과 구리가 0.886의 정확도를 보였으며, 칼륨을 제외한 나머지 성분은 0.914의 정확도를 기록하였다. 칼륨이 제거된 모델의 경우 정확도 0.943으로 모든 무기성분을 포함하여 분석한 모델의 정확도와 가장 근접한 수치를 보였다. 따라서 칼륨 성분이 질소결핍 여부를 판정하는데 가장 낮은 기여를 하는 것으로 판단되었다. 따라서 모든 성분이 포함된 모델이 가장 높은 0.971의 정확도를 보였기 때문에 부지화 잎의 질소결핍 여부를 구분하는 모델에는 모든 무기성분의 함량을 바탕으로 분석하였다.
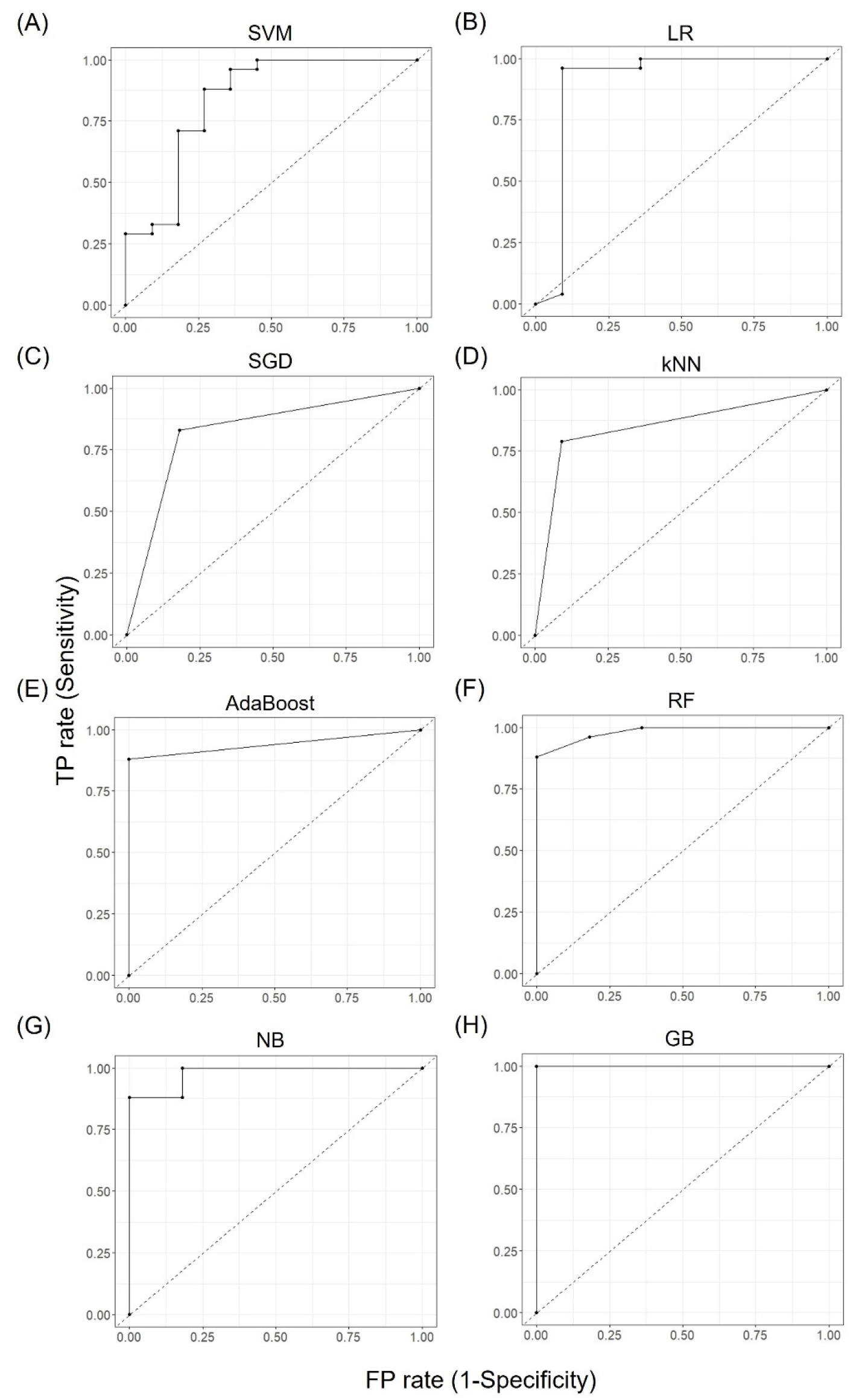
질소결핍 여부를 판단하는 머신러닝 모델
본 연구에서는 질소결핍 처리구와 정상구의 잎 성분분석을 통해서 질소와 다른 무기양분과의 상관관계를 바탕으로 무기양분의 함량 패턴에 따라 잎의 질소결핍 여부를 판정하는 8가지 모델을 구현해 보았다. 그 결과 각 모델의 성능평가지표에 대한 내용은 Table 1에 표기하였고, Fig. 4에는 테스트 데이터셋으로 분석된 각 모델의 AUC 그래프를 보여주고 있다. Fig. 5에는 역시 테스트 데이터셋을 대상으로 각 모델이 잎의 무기양분 데이터를 기반으로 잎의 질소결핍 여부를 구분한 결과를 보여주고 있다. Table 1에서 보듯이 GB이 정확도 0.971로 가장 뛰어난 분류성능을 보여주었다. 뿐만 아니라 F1, Precision, Recall 또한 다른 모델들보다 뛰어났다. AUC는 ROC curve의 아래면적을 의미하는데 이 면적이 1에 가까울수록 그 모델의 분류성능이 뛰어난 것으로 판단하게 된다. 즉, Table 1의 AUC 수치는 Fig. 4에서 확인할 수 있는데, SVM은 LR보다 작은 면적을 갖고 있어 분류성능이 LR보다 낮았으며, 역시 GB의 AUC가 다른 모델들보다 큰 것을 알 수 있었다. Fig. 5를 보면, 각 모델이 질소결핍 여부를 분류하기 위해 예측한 확률값을 보여주는데 y축의 값이 0에 가까울수록 잎의 질소가 결핍된 것으로 판단하며, 1에 가까울수록 질소함량이 정상인 잎으로 구분한다. SVM, LR, SGD, kNN 모델은 잎 질소함량이 2.5%를 넘는데도 불구하고 질소결핍으로 판단하는 경우가 많았으며, 반대로 질소결핍구임에도 불구하고 정상구로 잘못 분류하는 경우도 1건 이상 발생하였다(Fig. 5A~D). 그러나 AdaBoost, RF, NB모델에서는 질소결핍구를 잘못 분류하는 경우는 없었으나 정상 개체가 질소결핍으로 잘못 분류된 경우가 3건으로 동일하였다. 그러나 GB모델은 오직 단 하나의 샘플이 질소 농도가 3.0%에 가까웠음에도 불구하고 질소결핍으로 잘못 분류되었다.
Table 1.
Performance metrics of machine learning algorithms to classify nitrogen deficiency based on test dataset about the concentration of mineral nutrients from the leaves of Shiranuhi. The models were sorted by the accuracy of each model
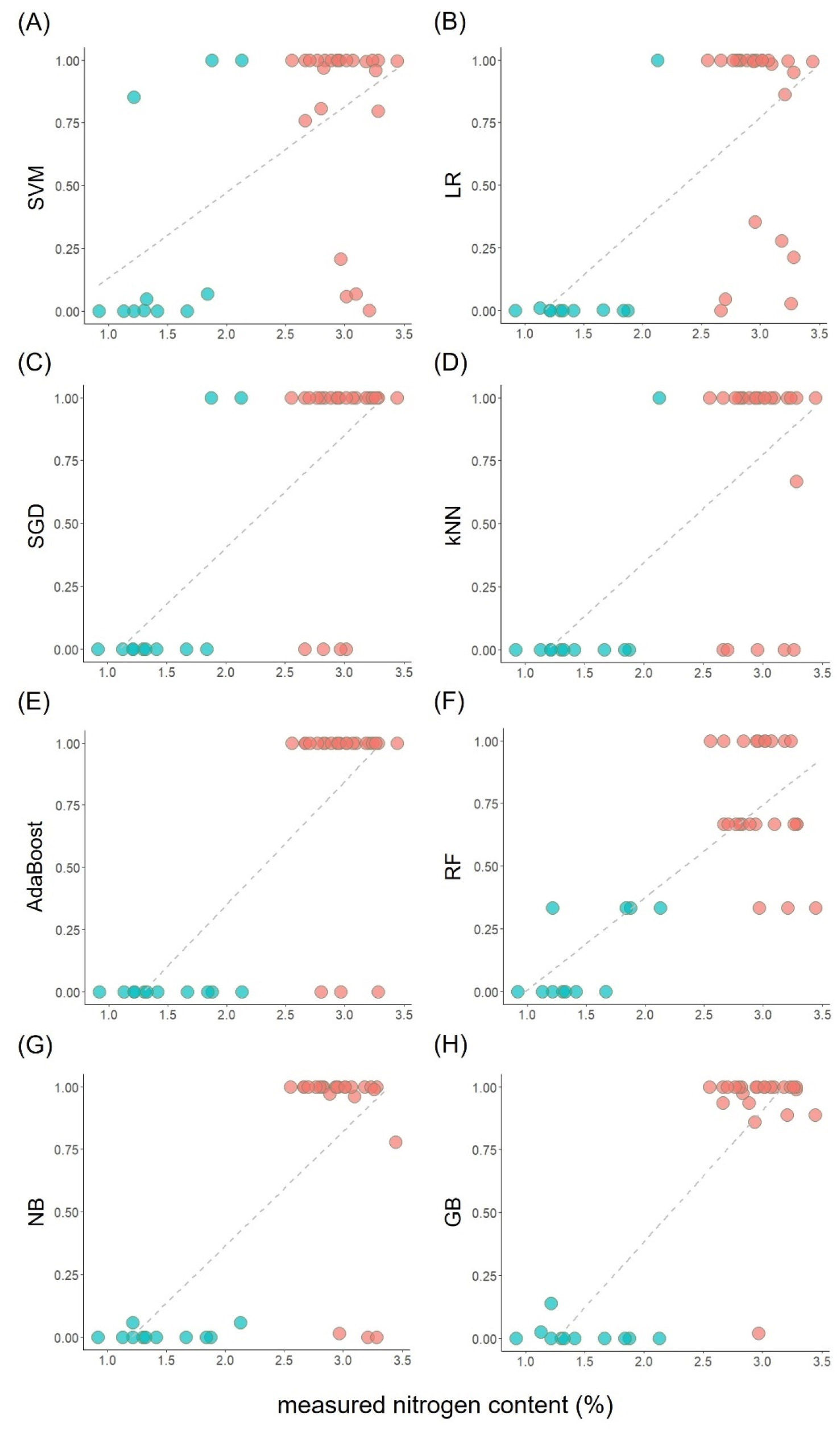
기존 문헌 보고에 따르면 감귤에서는 잎의 질소함량이 2.5% 미만이면 질소결핍으로 본다고 하였다(Bennett, 1993; Chapman, 1967; Thompson et al., 2003). 그러나 GB를 비롯한 여러 모델에서는 질소농도 2.2-2.3%를 기준으로 질소결핍 여부를 판정하였다. Fig. 5에서 각 모델의 회귀식은 다음과 같다: y = -0.21 + 0.34x (SVM); y = -0.49 + 0.42x (LR); y = -0.49 + 0.45x (SGD); y = -0.51 + 0.43x (kNN); y = -0.64 + 0.49x (AdaBoost); y = -0.36 + 0.37x (RF); y = -0.55 + 0.46x (NB); y = -0.66 + 0.52x (GB). 이러한 차이는 ICP-OES 장비를 활용해 부지화 잎의 무기성분 측정을 더욱 많이 수행하여 충분한 학습용 데이터셋을 확보하지 못하였으며, 그리고 적은 데이터에 기반하여 부트스트랩핑을 통해 생성된 데이터셋을 모델에 사용한 때문인 것으로 판단된다. 따라서 추후 질소결핍구 및 정상구의 부지화 나무를 더 확보하여 충분한 무기성분 측정자료를 획득한 후, 각 모델에 적용하여 잎의 질소결핍 여부를 더욱 정확히 분류할 수 있도록 개선할 계획이다.
적 요
본 연구에서는 부지화 잎의 무기양분 농도 측정 결과를 바탕으로 질소를 제외한 다른 무기양분의 함량을 통해서 잎의 질소결핍 여부를 구분하는 머신러닝 모델을 개발하였다. 그러기 위해서 부지화의 질소결핍구와 대조구의 잎 샘플을 분석한 36개의 데이터를 부트스트랩핑 방법을 통해서 학습용 데이터셋 1,000 여 개로 증량시켰다. 이를 이용해 학습한 각 모델을 테스트한 결과, gradient boosting 모델이 가장 우수한 분류성능을 보여주었다. 본 모델을 이용해 질소함량을 직접적으로 분석할 수 없는 경우, 잎의 무기성분 함량에 기반하여 질소결핍 가능성 여부를 판단해 질소가 부족한 부지화 나무를 분별하고, 정확한 질소함량을 측정하게 유도하여 그에 기초한 적정 질소비료 시비를 가능케 하고자 하였다.
